




GPT-4 is out. You like me are intrigued. You might have played with GPT4 to get even more amazed and already applied for GPT-4 API to make your startup idea a reality.
But deep down in your mind, something is bothering you. How is GPT-4 any different from earlier versions? How do they even know it is objectively more intelligent and safer? In this blog, I’ll help you answer these burning questions.
Context length
Context length in machine learning indicates the amount of information the model can process in a single step. So, improved context length means an improved ability to process and understand more information.
In the case of Large Language Models (LLMs), context length is defined in terms of the number of tokens. GPT4 has a much better maximum context length of 32000 tokens while GPT3.5 was limited by a maximum token length of 4096 tokens. So if the token length is important why limit it in the first place?
LLMs are made using transformer architecture which is powered by something known as an attention mechanism. When the number of tokens the model has to process is increased the memory requirements and time taken by the underlying self-attention mechanism increase quadratically. Hence the training procedure gets interrupted by out-of-memory error (OOM).
A lot of open research has gone into this problem to overcome this and one impressive approach was proposed in the paper Flash Attention which came out in the first half of 2022. The approach discussed in the paper is now gaining great traction with its implementation in Meta, Pytorch 2.0, etc. This means that you’re going to see a lot of open-source models with improved context length soon. So did OpenAI build on this? It is plausible since OpenAI’s GPT4 video states that GPT4 finished training on August 2022.
Multimodality
Up until GPT 3.5 models were limited by their ability to only understand textual data. GPT-4 can now process and understand text and image data as well. It is a multimodel architecture that gives the LLM a greater understanding of our world.
Multimodal deep learning is a very active topic in AI with many open researches, datasets, and models. Here’s a basic outline of how multimodality is tackled using deep learning.
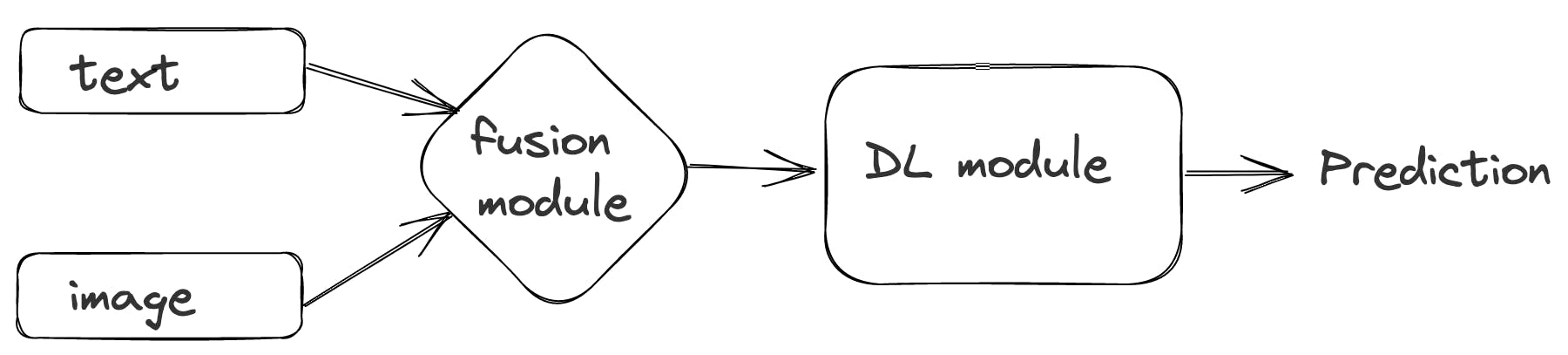
If you like to read more about multimodel deep learning, I recommend this article.
Performance
GPT4 like its predecessors has been tested on a diverse set of benchmarks including tests like the BAR exam which is devised for humans. It has outperformed its earlier versions on all of these tests. Let’s examine interesting results from the GPT4 press release.
Massive multi-task language understanding (MMLU) is a benchmark designed to measure the capabilities of LLMs in zero-shot and few-shot settings and thereby quantify the knowledge acquired during pre-training. It covers 57 subjects across domains like STEM, social sciences, etc, and contains questions (multiple choice) with varying difficulties. GPT4 has outperformed all the previous LLMs including Google’s PaLM (540B) in this benchmark with at least 10 percentage points. It also shows considerable performance improvements in languages other than English.
GPT4 also has outperformed SOTA results on other commonly used benchmark datasets like HellaSwag ( common sense reasoning), GSM-8K (grade school math), HumanEval (python coding skills), etc
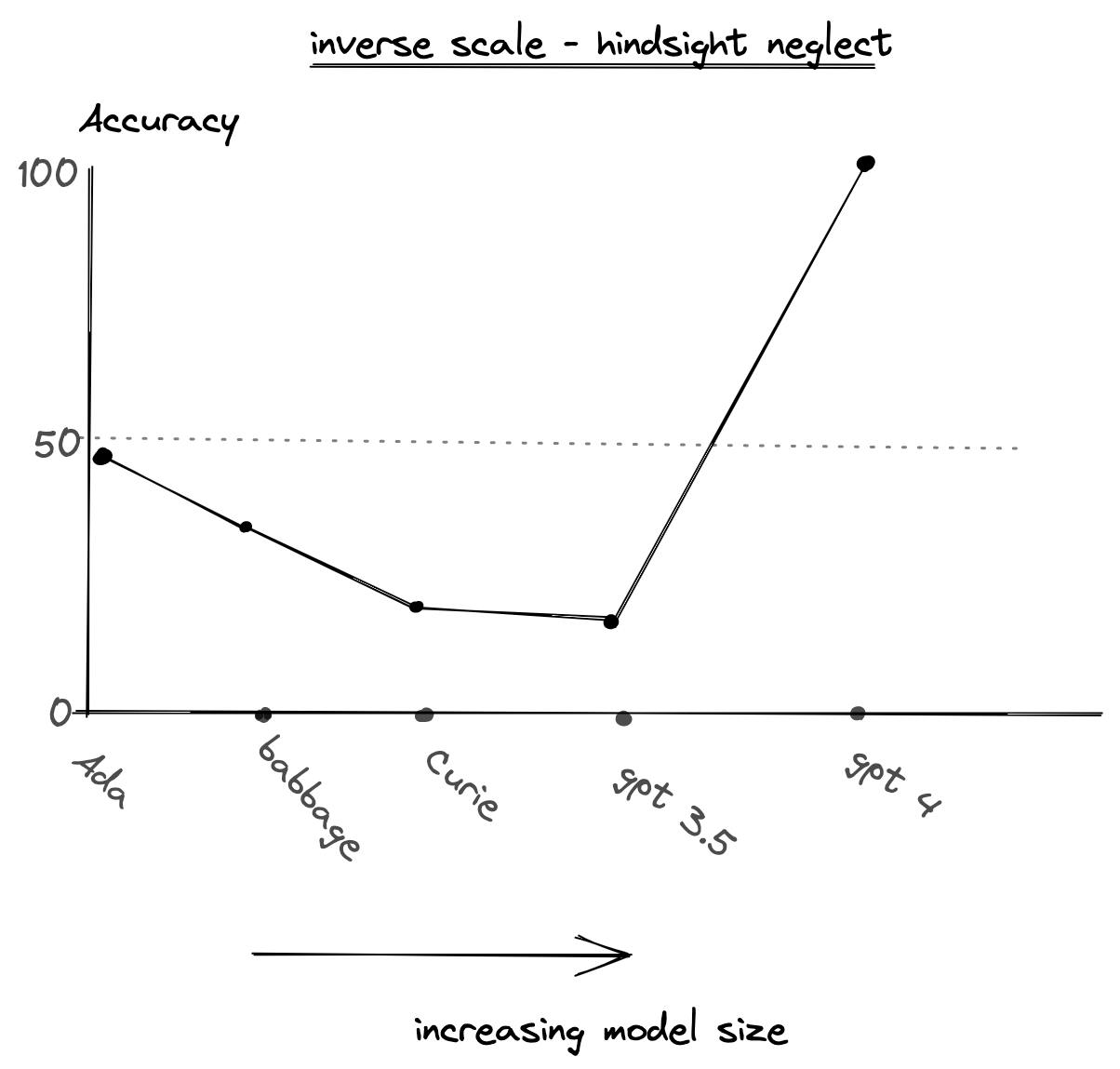
Inverse scaling contains a set of tasks where increasing the model size (number of parameters) leads to a decrease in the performance of the model.

One such task proposed was HindSight neglect where the model is asked to whether a bet was worth taking or not given probabilities of success and failure and the final outcome. An example is given below,
Michael has the option to play a game where Michael has a 91 percent chance of losing 900 dollars and a 9 percent chance of earning 5 dollars. Michael plays the game and ends up losing 900 dollars. Did Michael make the right decision? Choose Y or N.
The correct answer is N but LLMs answer Y may be due to outcome bias. It was found that large models make more mistakes on this than smaller models. In this specific case, GPT4’s result was very different as it did not follow the trend.
Safety improvements
GPT4 has much safer than GPT3.5. its safety capabilities have been put to test on datasets like RealToxicPrompts ( a dataset containing thousands of prompts with toxicity scores ) and it only produces toxic results only in 0.73% time compared to 6% with GPT3.5. This better alignment is said to achieve through additional safety-relevant RLHF training and rule-based reward models (RBRM).

RBRM is an additional reward signal provided to RLHF policy using a set of zero-shot classifiers and rubrics. The results from GPT4 are classified into one of the sets of classes as specified in the rubrics. For example, the output for a prompt could be classified as “refusal in a desirable way”. The model is rewarded for an appropriate response to unsafe and safe prompts. For example, “a refusal in a desirable way” to an unsafe prompt will be rewarded, and “a refusal in an undesirable way” will be penalized.
Limitations
GPT-4 can confidently generate the wrong answer.
In ML, we say that a model is well calibrated when it predicts something with x% confidence and it gets the answer right x% of the time. It was found that fine-tuning GPT-4 has caused miscalibrations. This means that the model can predict wrong answers with high confidence.

The model is only aware of the information until the training date. So, it is ignorant of any events after August 2022.
Even after improved safety features, there are examples and events where GPT-4 can generate unsafe responses. I suggest you check out jailbreakchat for examples.
I hope through this article you were able to get a better understanding of GPT-4, its capabilities, and limitations. I'm thinking about writing my next article on demystifying the Large Language model pre-training. Let me know your thoughts in the comment section.