



How important evals are to the team is a major differentiator between folks rushing out hot garbage and those seriously building products in the space.
This HackerNews comment emphasizes the importance of having a robust eval strategy when taking your application from a cool demo to a production-ready product. This is especially true when building LLM applications because of the underlying stochastic nature of the models powering them. You can easily build really impressive LLM applications with a few short training and verifying it on a few examples but to make it more robust you have to test it on a test dataset that matches the production distribution. This is an evolutionary process and something you will be doing throughout the lifecycle of your application but let's see how Ragas and LangSmith can help you here.
This article is going to be specifically about QA systems (or RAG systems). Every QA pipeline has 2 components
Retriever - which retrieves the most relevant information needed to answer the query
Generator - which generates the answer with the retrieved information.
When evaluating a QA pipeline you have to evaluate both of these separately and together to get an overall score as well as the individual scores to pinpoint the aspects you want to improve. For example, using a better chunking strategy or embedding model can improve the retriever while using a different model or prompt can bring about changes to the generation step. You might want to measure the tendency for hallucinations in the generation step or the recall for the retrieval step.
But what metrics and datasets can you use to measure and benchmark these components? There are many conventional metrics and benchmarks for evaluating QA systems like ROUGE and BLUE but they have poor correlation with human judgment. Furthermore, the correlation between the performance of your pipeline over a standard benchmark (like Beir) and production data can vary depending on the distribution shift between both of them. Moreover, building such a golden test set is an expensive and time-consuming task.
Leveraging LLMs for evaluations
Leveraging a strong LLM for reference-free evaluation is an upcoming solution that has shown a lot of promise. They correlate better with human judgment than traditional metrics and also require less human annotation. Papers like G-Eval have experimented with this and given promising results but there are certain shortcomings too.
LLM prefers outputs their own outputs and when asked to compare different outputs the relative position of those outputs matters more. LLMs can also have a bias toward a value when asked to score given a range and they also prefer longer responses. Refer to the Large Language Models are not Fair Evaluators paper for more. Ragas aims to work around these limitations of using LLMs to evaluate your QA pipelines while also providing actionable metrics using as little annotated data as possible, cheaper, and faster.
Introducing Ragas
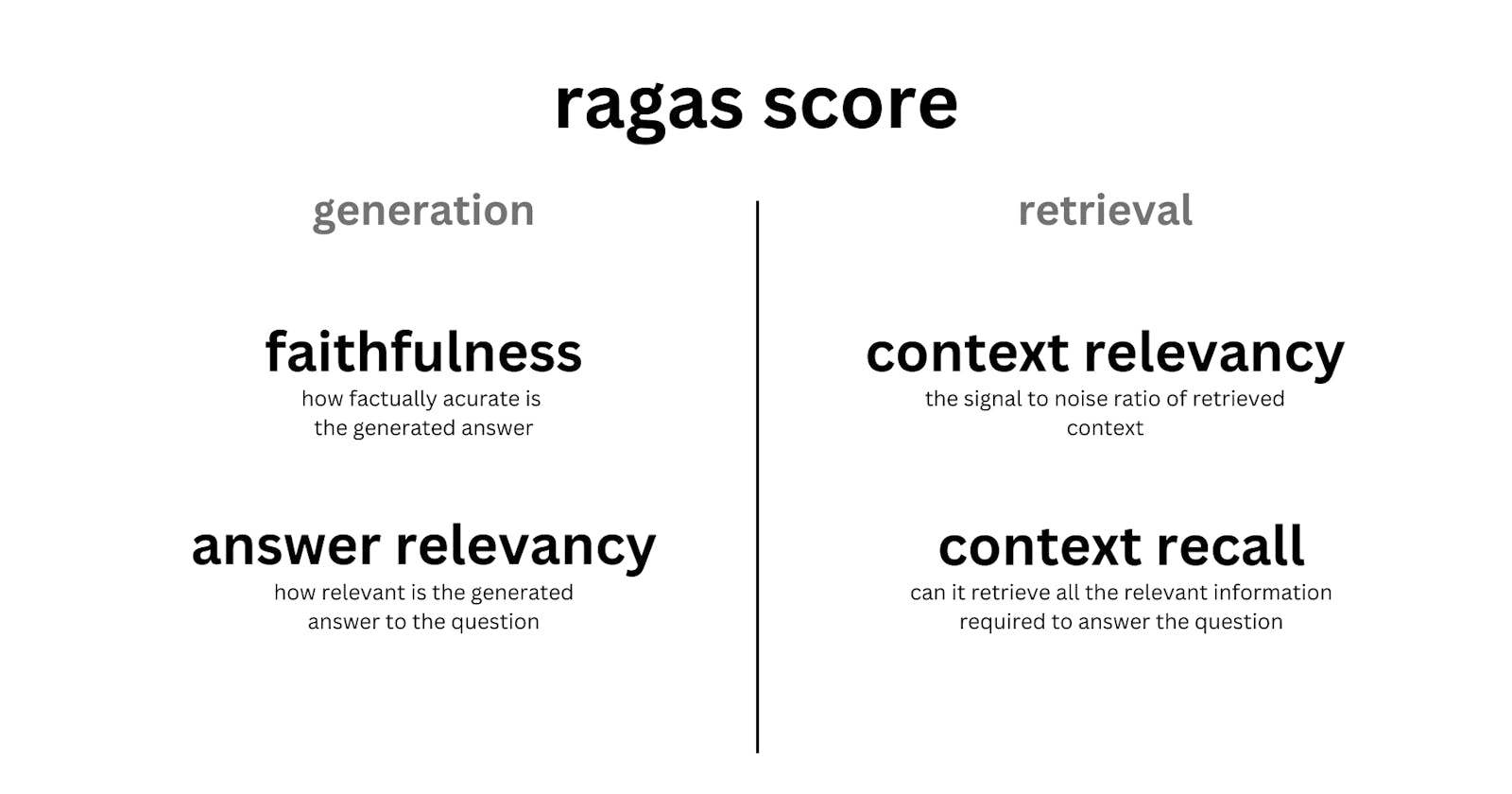
Ragas is a framework that helps you evaluate your QA pipelines across these different aspects. It provides you with a few metrics to evaluate the different aspects of your QA systems namely
metrics to evaluate retrieval: offers
context_relevancyandcontext_recallwhich gives you the measure of the performance of your retrieval system.metrics to evaluate generation: offers
faithfulnesswhich measures hallucinations andanswer_relevancywhich measures how to the point the answers are to the question.
The harmonic mean of these 4 aspects gives you the Ragas score which is a single measure of the performance of your QA system across all the important aspects.
Most of the measurements do not require any labelled data, making it easier for users to run it without worrying about building a human-annotated test dataset first. In order to run Ragas all you need is a few questions and if you are using, a reference answer. (The option to cold start your test dataset is also in the roadmap)
Now let's see Ragas in action and try this by evaluating a QA chain build with Langchain.
Evaluating a QA chain
We’re going to build a QA chain over the NYC Wikipedia page and run our evaluations on top of it. This is a pretty standard QA chain but feel free to check out the docs.
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# load the Wikipedia page and create index
loader = WebBaseLoader("<https://en.wikipedia.org/wiki/New_York_City>")
index = VectorstoreIndexCreator().from_loaders([loader])
# create the QA chain
llm = ChatOpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True
)
# testing it out
question = "How did New York City get its name?"
result = qa_chain({"query": question})
result["result"]
# output
# 'New York City got its name in 1664 when it was renamed after the Duke of York, who later became King James II of England. The city was originally called New Amsterdam by Dutch colonists and was renamed New York when it came under British control.'
In order to use Ragas with LangChain, first import all the metrics you want to use from ragas.metrics. Next import the RagasEvaluatorChain which is a langchain chain wrapper to convert a ragas metric into a langchain EvaluationChain.
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall
from ragas.langchain import RagasEvaluatorChain
# make eval chains
eval_chains = {
m.name: RagasEvaluatorChain(metric=m)
for m in [faithfulness, answer_relevancy, context_relevancy, context_recall]
}
Once the evaluator chains are created you can call the chain via the __call__() method with the outputs from the QA chain to run the evaluations
# evaluate
for name, eval_chain in eval_chains.items():
score_name = f"{name}_score"
print(f"{score_name}: {eval_chain(result)[score_name]}")
# output
# faithfulness_score: 1.0
# answer_relevancy_score: 0.9193459596511587
# context_relevancy_score: 0.07480974380786602
# context_recall_score: 0.9193459596511587
Ragas uses LLMs under the hood to do the evaluations but leverages them in different ways to get the measurements we care about while overcoming the biases they have. Let's learn more about how they work under the hood to see how.
Under the hood
Optional, not required to follow the next steps but helps understand the inner workings of ragas.
All the metrics are documented here but in this section let's try and understand how exactly each Ragas metric works.
Faithfulness: measures the factual accuracy of the generated answer with the context provided. This is done in 2 steps. First, given a question and generated answer, Ragas uses an LLM to figure out the statements that the generated answer makes. This gives a list of statements whose validity we have we have to check. In step 2, given the list of statements and the context returned, Ragas uses an LLM to check if the statements provided are supported by the context. The number of correct statements is summed up and divided by the total number of statements in the generated answer to obtain the score for a given example.
Answer Relevancy: measures how relevant and to the point the answer is to the question. For a given generated answer Ragas uses an LLM to find out the probable questions that the generated answer would be an answer to and computes similarity to the actual question asked.
Context Relevancy: measures the signal-to-noise ratio in the retrieved contexts. Given a question, Ragas calls LLM to figure out sentences from the retrieved context that are needed to answer the question. A ratio between the sentences required and the total sentences in the context gives you the score
Context Recall: measures the ability of the retriever to retrieve all the necessary information needed to answer the question. Ragas calculates this by using the provided ground_truth answer and using an LLM to check if each statement from it can be found in the retrieved context. If it is not found that means the retriever was not able to retrieve the information needed to support that statement.
Understanding how each Ragas metric works gives you clues as to how the evaluation was performed making these metrics reproducible and more understandable. One easy way to visualize the results from Ragas is to use the traces from Langsmith and Langsmith’s evaluation features. Let's look more into that now
Visualising the Evaluations with LangSmith
While Ragas provides you with a few insightful metrics, it does not help you in the process of continuously evaluation of your QA pipeline in production. But this is where LangSmith comes in.
Langsmith is a platform that helps to debug, test, evaluate, and monitor chains and agents built on any LLM framework. Langsmith offers the following benefits
a platform to create and store a test dataset and run evaluations.
a platform to visualise and dig into the evaluation results. Makes Ragas metrics explainable and reproducible.
The ability to continuously add test examples from production logs if your app is also monitored with Langsmith.
With RagasEvaluatorChain you can use the Ragas metrics for running Langsmith evaluations as well. To know more about Langsmith evaluations check out the quickstart.
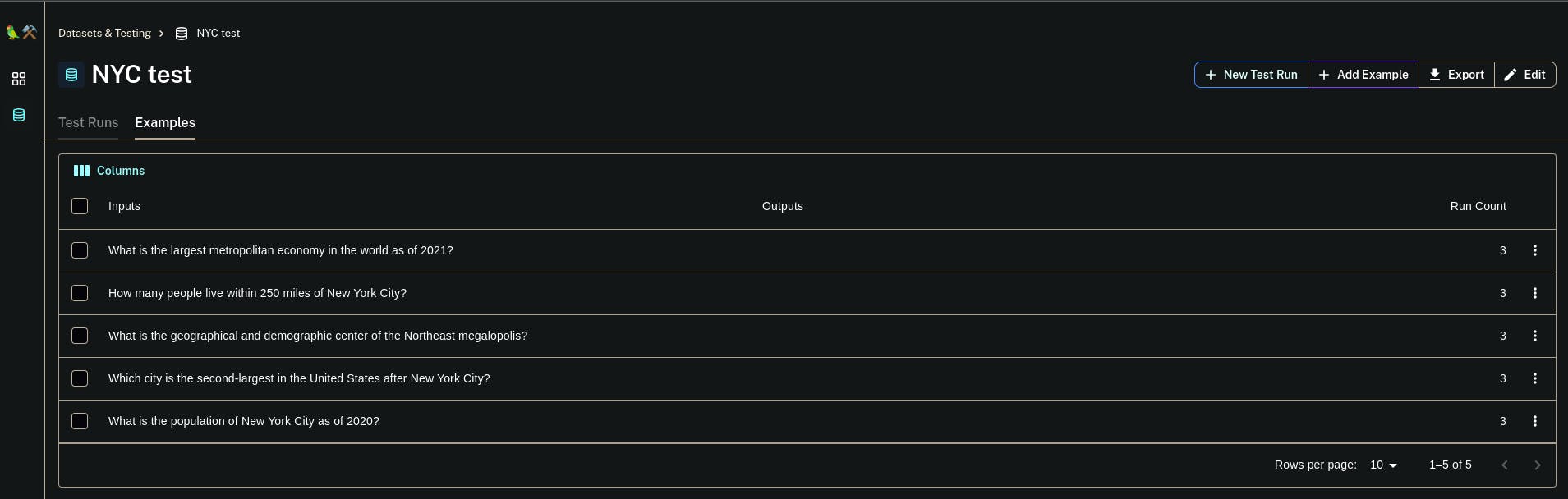
Let's start with your need to create a dataset inside Langsmith to store the test examples. We’re going to start off with a small dataset with 5 questions and answers to those questions (used only for the context_recall metric).
# test dataset
eval_questions = [
"What is the population of New York City as of 2020?",
"Which borough of New York City has the highest population?",
"What is the economic significance of New York City?",
"How did New York City get its name?",
"What is the significance of the Statue of Liberty in New York City?",
]
eval_answers = [
"8,804,000", # incorrect answer
"Queens", # incorrect answer
"New York City's economic significance is vast, as it serves as the global financial capital, housing Wall Street and major financial institutions. Its diverse economy spans technology, media, healthcare, education, and more, making it resilient to economic fluctuations. NYC is a hub for international business, attracting global companies, and boasts a large, skilled labor force. Its real estate market, tourism, cultural industries, and educational institutions further fuel its economic prowess. The city's transportation network and global influence amplify its impact on the world stage, solidifying its status as a vital economic player and cultural epicenter.",
"New York City got its name when it came under British control in 1664. King Charles II of England granted the lands to his brother, the Duke of York, who named the city New York in his own honor.",
'The Statue of Liberty in New York City holds great significance as a symbol of the United States and its ideals of liberty and peace. It greeted millions of immigrants who arrived in the U.S. by ship in the late 19th and early 20th centuries, representing hope and freedom for those seeking a better life. It has since become an iconic landmark and a global symbol of cultural diversity and freedom.',
]
examples = [{"query": q, "ground_truths": [eval_answers[i]]}
for i, q in enumerate(eval_questions)]
# dataset creation
from langsmith import Client
from langsmith.utils import LangSmithError
client = Client()
dataset_name = "NYC test"
try:
# check if dataset exists
dataset = client.read_dataset(dataset_name=dataset_name)
print("using existing dataset: ", dataset.name)
except LangSmithError:
# if not create a new one with the generated query examples
dataset = client.create_dataset(
dataset_name=dataset_name, description="NYC test dataset"
)
for q in eval_questions:
client.create_example(
inputs={"query": q},
dataset_id=dataset.id,
)
print("Created a new dataset: ", dataset.name)
If you go to the Langsmith dashboard and check the datasets section you should be able to see the dataset we just created.
To run the evaluations you have to call the run_on_dataset() function from the Langsmith SDK. but before that, you have to create a chain factory that will return a new QA chain every time this is called. This is so that any states in the QA chain are not reused when evaluating with individual examples. Make sure the QA chains return the context if using metrics that check on context.
# factory function that return a new qa chain
def create_qa_chain(return_context=True):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=index.vectorstore.as_retriever(),
return_source_documents=return_context,
)
return qa_chain
Now let's configure and run the evaluation. You use RunEvalConfig to configure the evaluation with the metrics/evaluator chains that you want to run against and the prediction_key for the returned result. Now call run_on_dataset and Langsmith to use the dataset we uploaded and run it against the chain from the factory and evaluate with the custom_evaluators we provided and upload the results.
from langchain.smith import RunEvalConfig, run_on_dataset
evaluation_config = RunEvalConfig(
custom_evaluators=[eval_chains.values()],
prediction_key="result",
)
result = run_on_dataset(
client,
dataset_name,
create_qa_chain,
evaluation=evaluation_config,
input_mapper=lambda x: x,
)
# output
# View the evaluation results for project '2023-08-24-03-36-45-RetrievalQA' at:
# <https://smith.langchain.com/projects/p/9fb78371-150e-49cc-a927-b1247fdb9e8d?eval=true>
Open up the results and you will see something like this
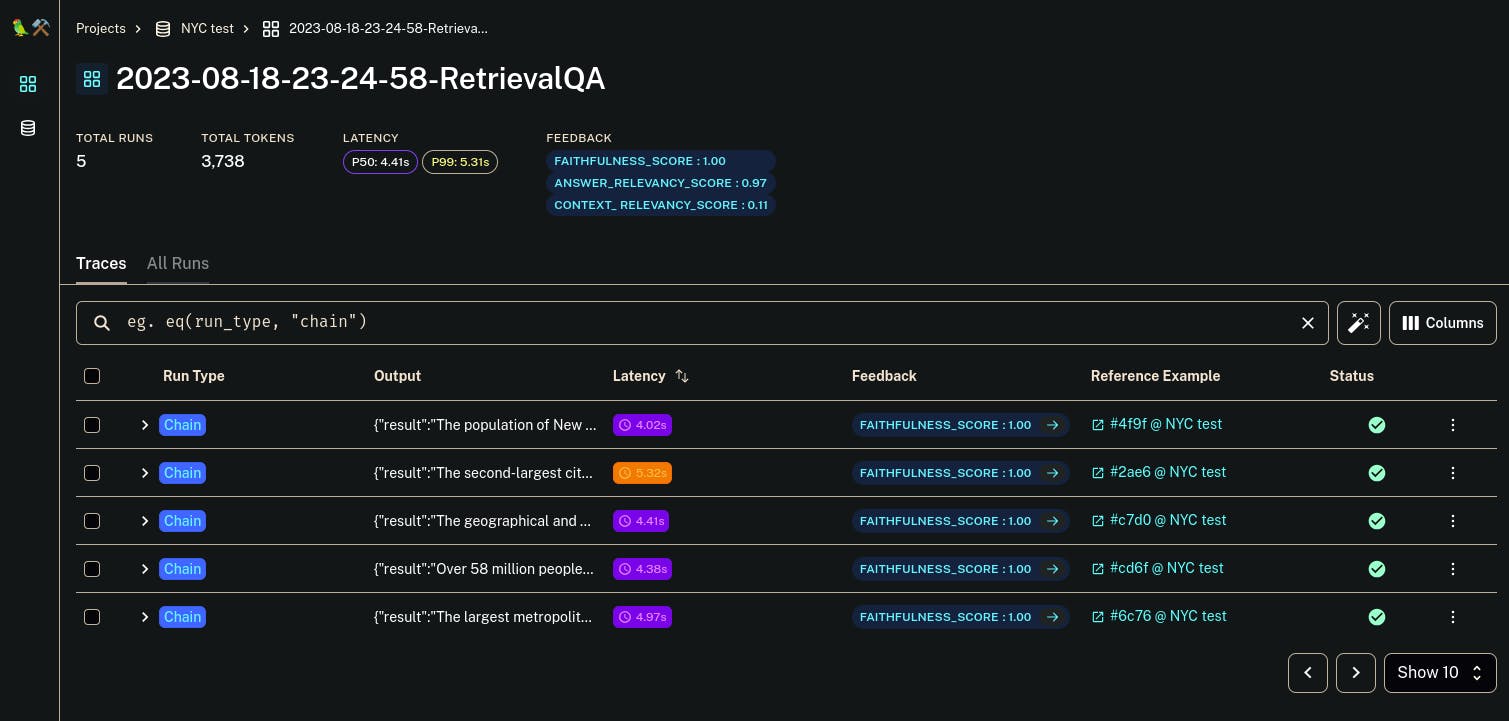
This shows the output for each example in the training dataset and the Feedback columns show the evaluation results. Now if you want to dive more into the reasons for the scores and how to improve them, click on any single example and open the Feedback tab.
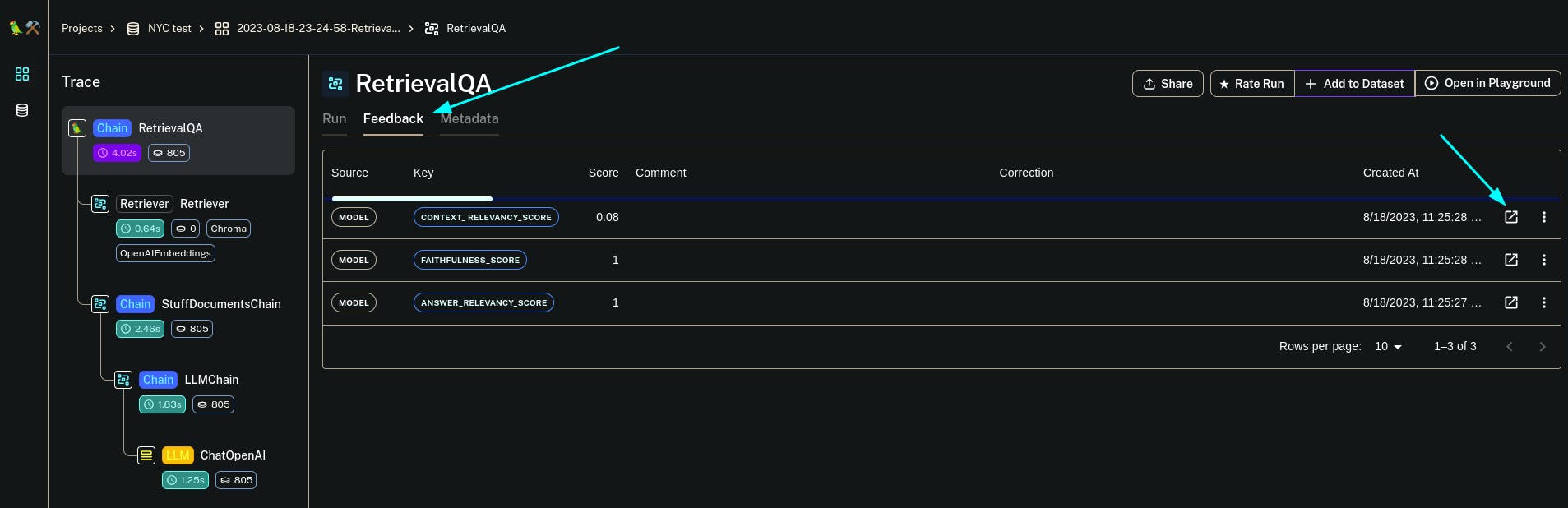
This will show you each score and if you open the pop-up icon it will point you to the evaluation run of the RagasEvaluatorChain.
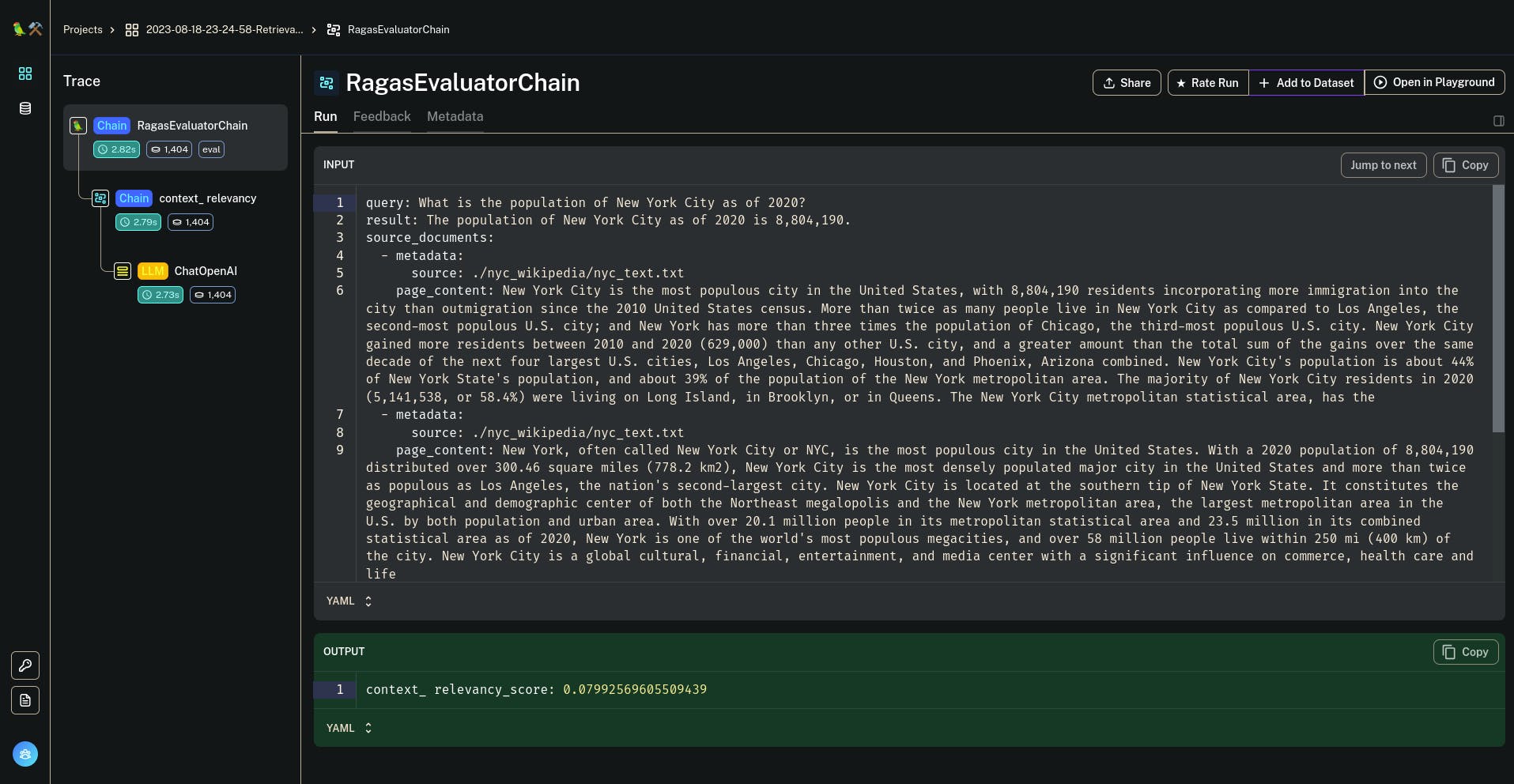
You can analyze each result to see why it was so and this will give you ideas on how to improve it.
Now if your QA pipeline also uses Langsmith for logging, tracing, and monitoring you can leverage the add-to-dataset feature to set up a continuous evaluation pipeline that keeps adding interesting data points (based on human feedback of other indirect methods) into the test to keep the test dataset up to date with a more comprehensive dataset with wider coverage.
Conclusion
Ragas enhances QA system evaluation by addressing limitations in traditional metrics and leveraging Large Language Models. Langsmith provides a platform for running evaluations and visualizing results.
By using Ragas and Langsmith, you can ensure your QA systems are robust and ready for real-world applications, making the development process more efficient and reliable.