





The emergence of LLMs has opened up a venue for tackling problems that were earlier thought impossible. The plethora of LLM-based applications is proof of this. But the one question still remains a mystery, how to effectively evaluate LLM-based applications?
We will try and solve that mystery through this article by understanding methods used to benchmark LLMs and discussing SOTA methods, available frameworks, and challenges in evaluating LLM-based applications.
Benchmarking LLMs
LLMs are primarily evaluated on open task-specific datasets to analyze their capabilities in doing a variety of tasks like summarisation, open book question answering, etc. There are several public benchmarks available as shown in the table. The metrics used in benchmarking LLMs vary with tasks. Most of the tasks are evaluated using traditional metrics such as exact match, which we will cover in the next section.
| Benchmark | Number of tasks |
| Beyond the Imitation Game Benchmark (BIG-bench) | 214 |
| lm-evaluation harness | 200+ |
| Super GLUE | 9 |
| GLUE | 9 |
| Abstraction and Reasoning corpus | 400 |
| Inverse scaling prize |
One of the major concerns about the usage of these benchmarks is that the model could have been exposed to datasets during the training or finetuning stage. This violates the fundamental rule that evaluation sets should be exclusive of training data.
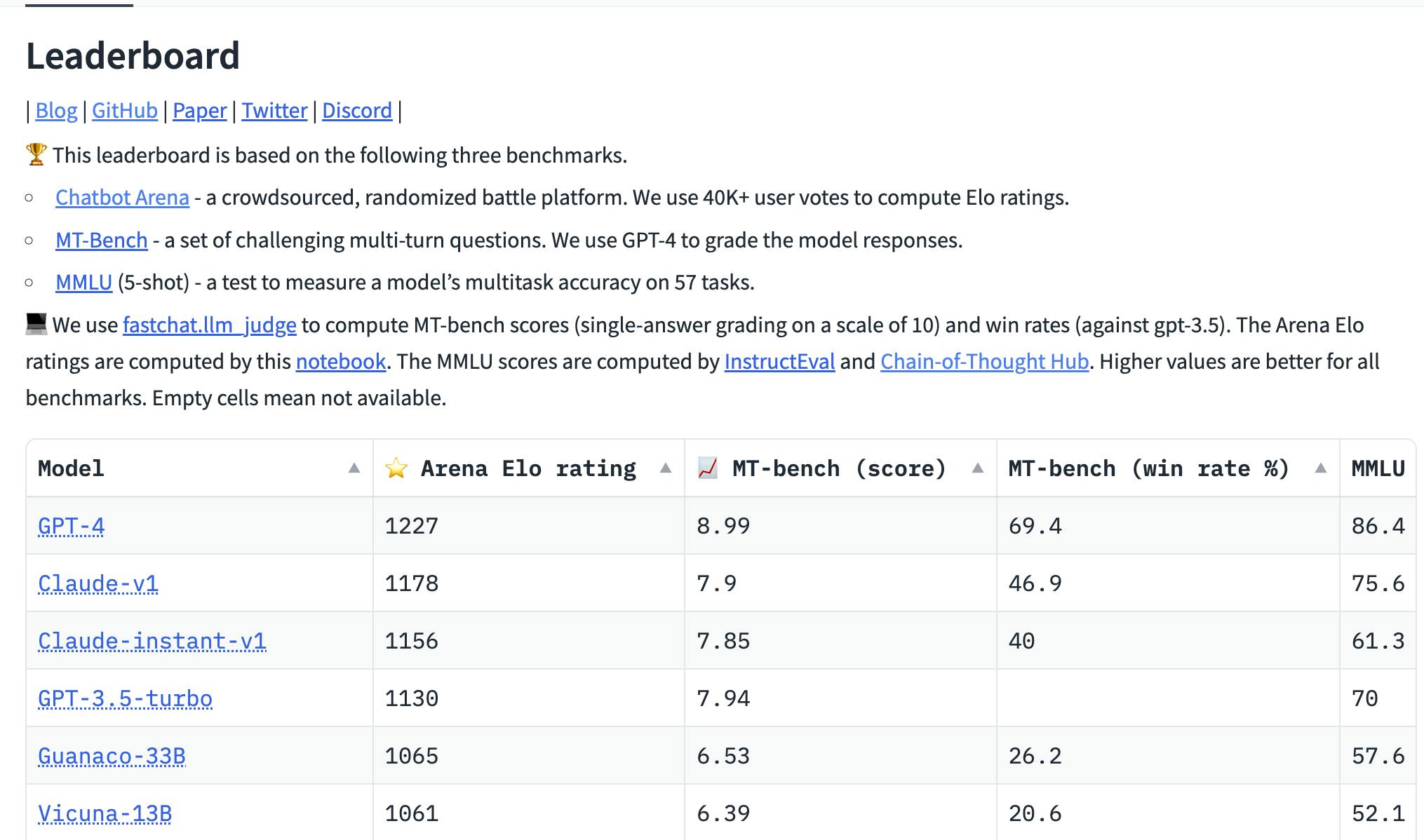
LLM leaderboards
LLM leaderboards provide a living benchmark for different foundational and instruction-finetuned LLMs. While the foundational LLM are evaluated on the open datasets their instruction finetuned versions are mostly evaluated using an Elo-based rating system.
Open LLM leaderboard: Provided a wrapper on top of the LM evaluation harness
HELM: Evaluates Open LLMs on a wide variety of open datasets and metrics.
Chatbot Arena: Elo rating for instruction finetuned LLMs
Evaluation metrics
Evaluation metrics for LLM can be broadly classified into traditional and nontraditional metrics. Traditional evaluation metrics rely on the arrangement and order of words and phrases in the text and are used in combination where a reference text (ground truth) exists to compare the predictions against. Nontraditional metrics make use of semantic structure and capabilities of language models for evaluating generated text. These techniques can be used with and without a reference text.
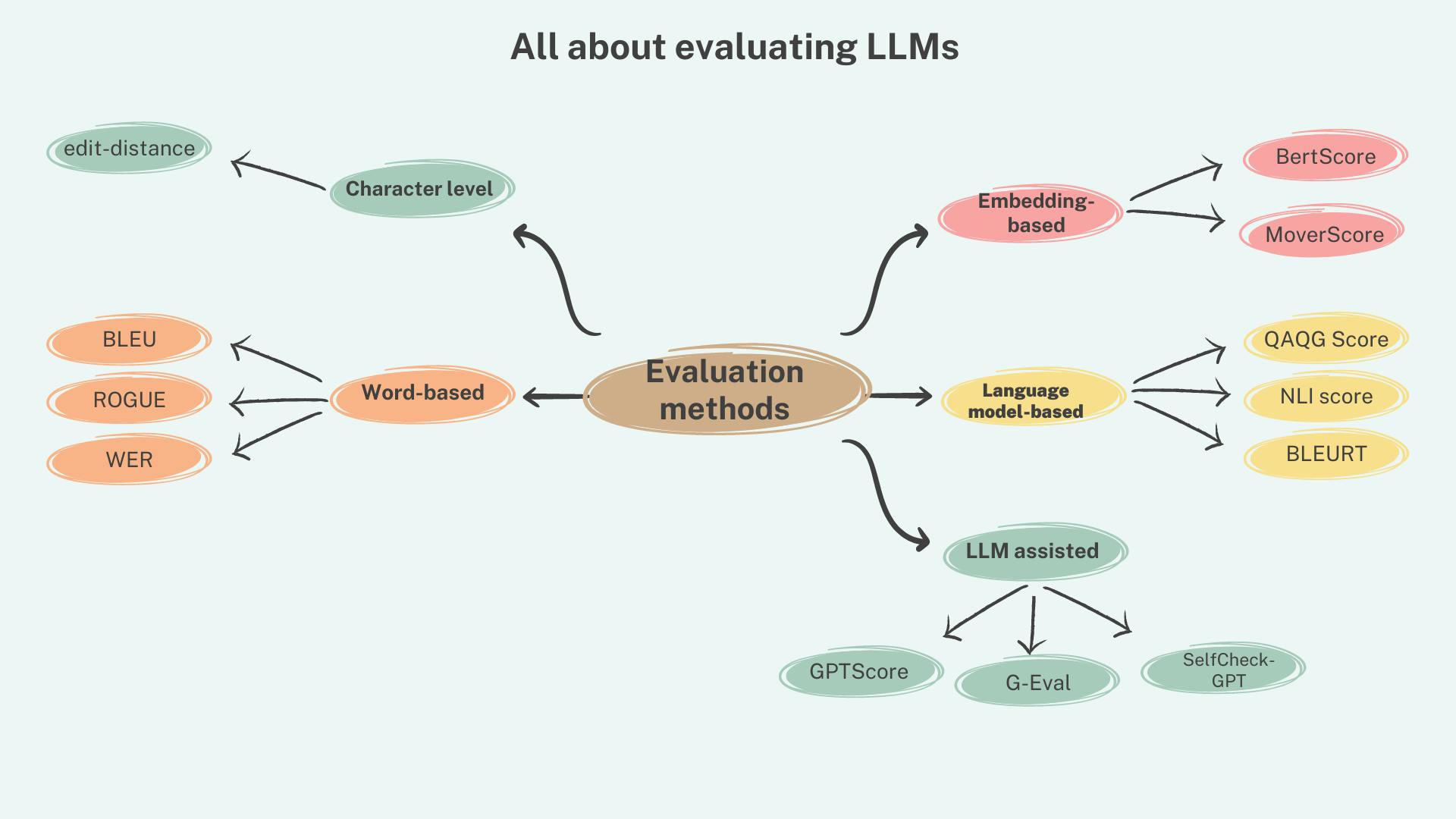
Traditional metrics
In this section, we will review some of the popular traditional metrics and their use cases. These metrics operate on the character/word/phrase level.
WER (Word Error Rate): There is a family of WER-based metrics which measure the edit distance 𝑑 (𝑐, 𝑟), i.e., the number of insertions, deletions, substitutions and, possibly, transpositions required to transform the candidate into the reference string.
Exact match: measures the accuracy of candidate text by matching the generated text with the reference text. Any deviation from reference text will be counted as incorrect. This is only suitable in the case of extractive and short-form answers where minimal or no deviation from the reference text is expected.
BLEU (Papineni et al.): evaluates candidate text based on how many ngrams in the generated text appear in reference text. This was originally proposed to evaluate machine translation systems. Multiple n-gram scores (2gram/3gram) can be calculated and combined using geometric average (BLEU-N). Since it is a precision-based metric, it does not penalize False negatives.
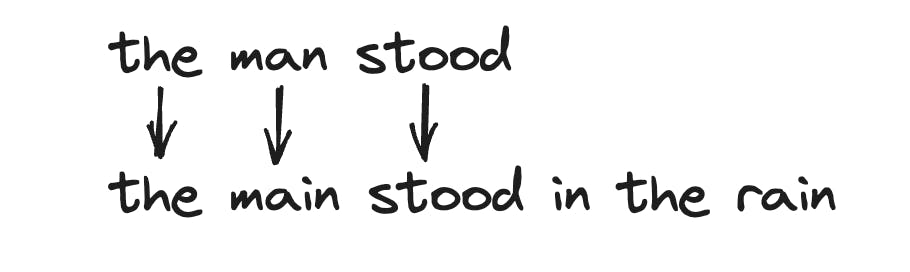
$$precision = {TP \over (TP + FP)} = {3 \over (3+0)} = 1$$
- ROGUE (Lin et al. 2004): This is similar to BLEU-N in counting n-gram matches but is based on recall. A variation of ROGUE, ROUGE-L measures the longest common subsequence (LCS) between a pair of sentences.
Other than these, there are other metrics like METEOR, General Text Matcher (GTM), etc. These metrics are very much constrained and do not go along with the current generational capabilities of large language models. Even though these metrics are currently only suited for tasks and datasets with short-form, extractive, or multi-choice answers, these methods or derivatives are still used as evaluation metrics in many of the benchmarks.
Nontraditional metrics
Nontraditional metrics for evaluating generated text can be further classified as embedding-based and LLM-assisted methods. While embedding-based methods leverage token or sentence vectors produced by deep learning models LLM assisted methods to form paradigms and leverage language models' capabilities to evaluate candidate text.
Embedding based methods
The key idea here is to leverage vector representation of text from DL models that represent rich semantic and syntactic information to compare the candidate text to reference text. The similarity of candidate text with reference text is quantified using methods such as cosine similarity.
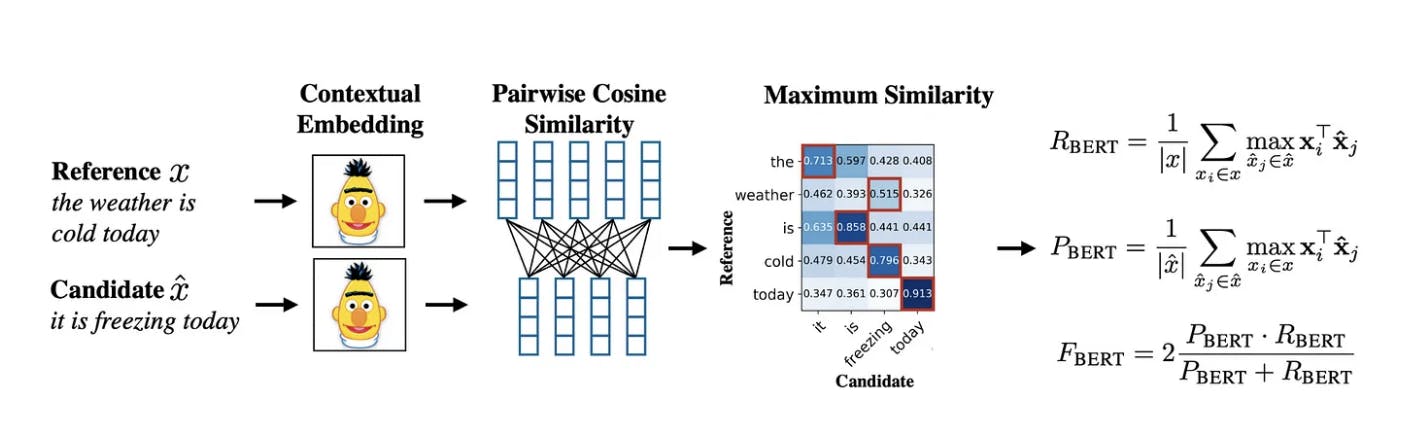
BERTScore (Zhang et al. 2019): This is a bi-encoded-based approach, ie the candidate text and reference text are fed into the DL model separately to obtain embeddings. The token-level embeddings are then used to calculate the pairwise cosine similarity matrix. Then similarity scores of most similar tokens from reference to candidates are selected and used to calculate precision, recall, and f1 score.
MoverScore (Zhao et al. 2019): uses the concept of word movers distance which suggests that distances between embedded word vectors are to some degree semantically meaningful ( vector(king) - vector(queen) = vector(man) ) and uses contextual embeddings to calculate Euclidean similarity between n-grams. In contrast to BERTscore which allows one-to-one hard matching of words, MoverScore allows many-to-one matching as it uses soft/partial alignments.
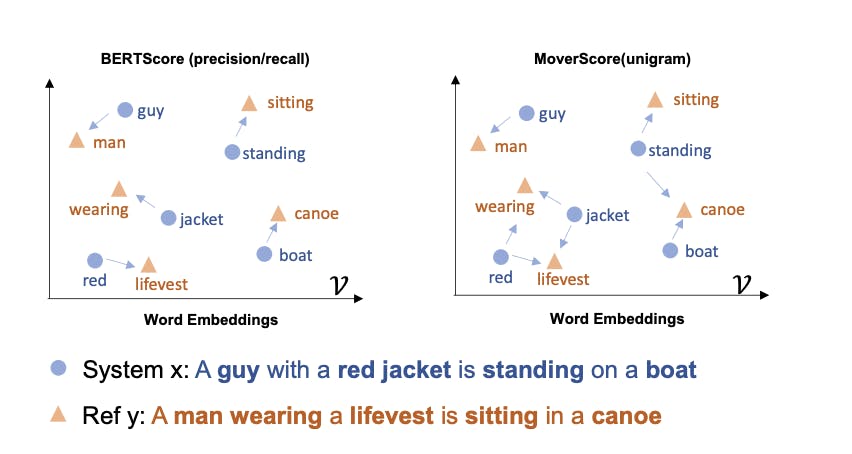
Even though embeddings-based methods are robust they assume that training and test data are identically distributed which may not always be the case.
Other Language model-based metrics
Entailment score: This method leverages the natural language inference capabilities of language models to judge NLG. There are different variants of this method but the basic concept is to score the generation by using an NLI model to produce the entailment score against the reference text. This method can be very useful to ensure faithfulness for text-grounded generation tasks like text summarization.

BLEURT (Sellam et al.): Introduces an approach to combine expressivity and robustness by pre-training a fully learned metric on large amounts of synthetic data, before fine-tuning it on human ratings. The method makes use of the BERT model to achieve this. To generalize the model for evaluating any new task or domain a new pre-training approach was proposed which involves an additional pre-training on synthetic data. Text segments from Wikipedia are collected and then augmented with techniques like word-replacements, back-translation, etc to form synthetic pairs $(x,x')$ and then trained on objectives like BLUE, ROGUE scores, back-translation probability, natural language inference, etc.
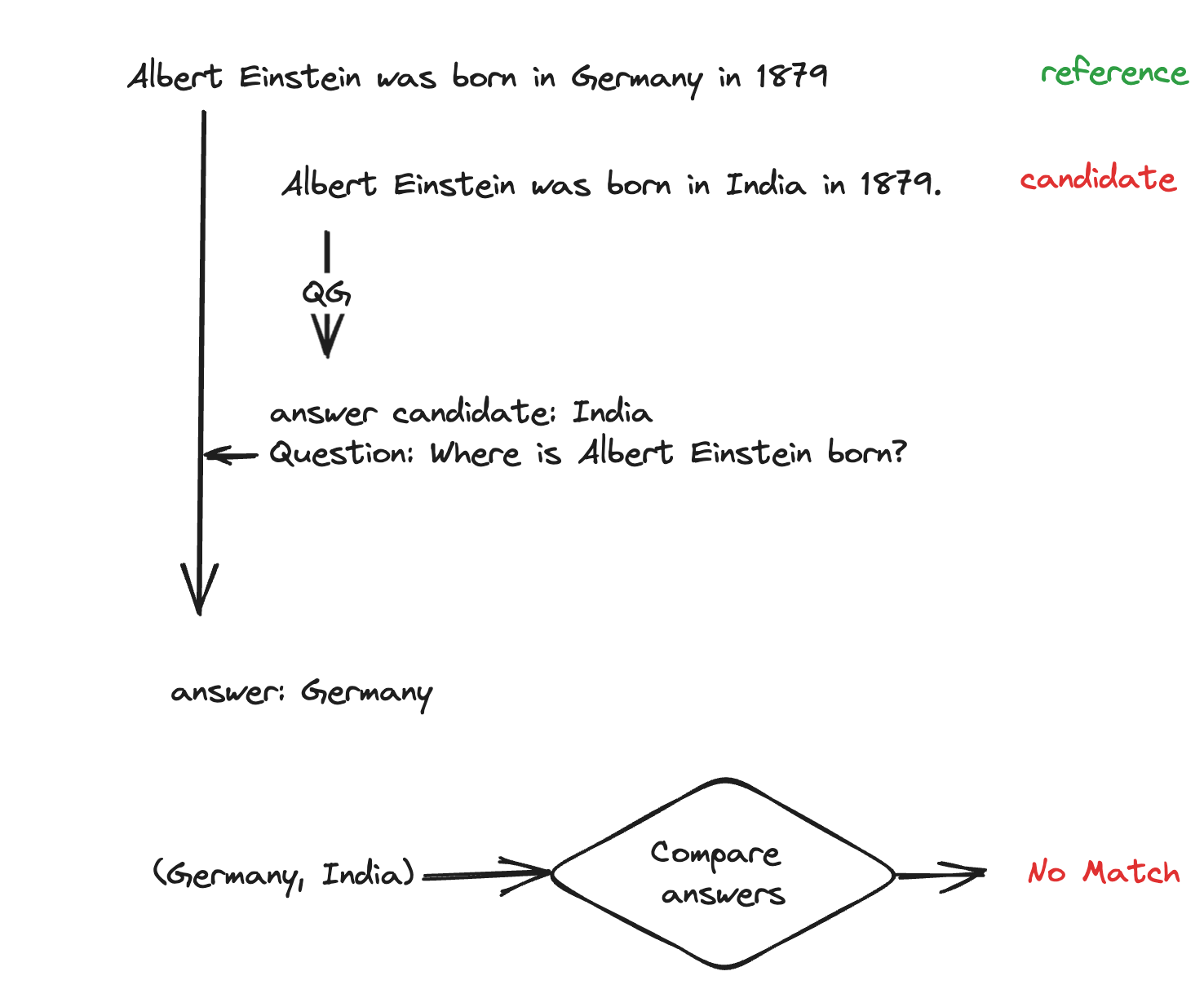
Question Answering - Question generation (QA-QG) (Honovich et. al): This paradigm can be used to measure the consistency of any candidate with reference text. The method works by first forming pairs of (answer candidates, questions) from the candidate text and then comparing and verifying the answers generated for the same set of questions given the reference text.
LLM assisted methods
As the name indicates the methods discussed in this section make use of large language models to evaluate LLM generations. The caveat here is to leverage LLMs capabilities and form paradigms to minimize the effect of different biases that LLMs might have like preferring one’s own output over other LLMs' output.
GPTScore (Fu et. al 2023) is One of the earliest approaches to using LLM as evaluators. The work explores the ability of ability if LLM in evaluating multiple aspects of generated text such as informativeness, relevancy, etc. This required defining an evaluation template \(T(.)\) suitable for each of the desired aspects. The approach assumes that the LLM will assign higher token probabilities for higher-quality generations and uses the conditional probability of generating the target text (hypothesis) as an evaluation metric. For any given prompt d, candidate response h, context S and aspect a, the GPT score is given by
$$GPTscore(h|a,S,d) = \sum logp(h_t|h_{
G-Eval (Liu et al. 2023) is also a very similar approach to GPTscore as the generated text is evaluated based on the criteria but unlike GPTscore directly performs evaluation by explicitly instructing the model to assign a score to generated text in the 0 to 5 range. LLMs as known to have some bias during score assignment like preferring integer scores and bias towards particular numbers in the given range (for example 3 in 0-5 scale). To tackle the output score is multiplied by the token probability \(p(i)\)
$$Score =\sum p(s_i) * s_i$$
Even though both of these methods can be used for multi-aspect evaluating including factuality, a better method to detect and quantify hallucinations without a reference text was proposed in SelfCheckGPT (Manakul et al. 2023) which leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. To measure information consistency between the generated responses one can use the QA-QG paradigm, BERTScore, Entailment score, n-gram, etc.
Possible pitfalls
With the emergence of highly capable large language models, the trend is going in the direction of using LLM itself to evaluate NLG. While this method has been shown to have a high correlation with human judgments (Wang et al. 2023) here are some issues with this approach
A Preliminary Study) some of the work has revealed the pitfalls of this approach. Works like (Wang et al. 2023) have shown that LLM has a positional bias because of which it prefers response in a particular position as better.
LLM has also shown to prefer integers when assigning scores to candidate responses.
LLMs are also stochastic in nature which makes them assign different scores to the same output when invoked separately.
When used to compare answers, it was found that GPT4 prefers its style of answering against even human-written answers.
Evaluating LLM based application
Choosing evaluation metrics
Evaluation metrics for LLM applications are chosen based on the mode of interaction and type of expected answer. There are primarily three forms of interactions with LLM
knowledge-seeking: LLM is provided with a question or instruction and a truthful answer is expected. example, what is the population of India?
Text grounded: LLM is provided with a text and instruction and expects the answer to be fully grounded on the given text. example, summarise the given text.
Creativity: LLM is provided with a question or instruction and a creative answer is expected. example, write a story about Prince Ashoka.
For each of these interactions or tasks, the type of answer expected can be an extractive, abstractive, short-form, long-form, or multi-choice.
For example, for an application of LLM in summarisation (text grounded + abstractive) of scientific papers, the faithfulness and consistency of the results with the original document are non-trivial.
Evaluating the evaluation method!
Once you have formulated an evaluation strategy that suits your application you should evaluate your strategy before trusting it to quantify the performance of your experiments. Evaluation strategies are evaluated by quantifying their correlation against human judgment.
Obtain or annotate a test set containing golden human annotated scores
Score the generations in the test set using your method.
Measure the correlation between human annotated scores and automatic scores using correlation measures like the Kendall rank correlation coefficient.
A score of 0.7 or above is generally regarded as good enough. This can be also used to improve the effectiveness of your evaluation strategy.
Building your evaluation set
Two fundamental criteria to ensure while forming the evaluating set for any ML problem are
The dataset should be large enough to yield statistically meaningful results
It should represent the data that is expected in production as a whole as much as possible.
Forming an evaluating set for LLM-based applications can be done incrementally. LLMs can also be leveraged to generate queries for the evaluation set using a few shot prompting, tools like auto-evaluator can help with this.
An evaluation set curation with ground truth is expensive and time-consuming, and maintaining such a golden annotated test set against data drift is a very challenging task. This is something to try If an unsupervised LLM-assisted methodology is not correlating well with your objectives. The presence of a reference answer can help in increasing the effectiveness of evaluation in certain aspects like factuality.
Tools
OpenAI Evals
Evals is an open-source framework for evaluating LLM generations. Using this framework you can evaluate the completions for instructions against a reference ground truth that you have defined. It gives the flexibility to modify and add datasets, and new completions (for example, chain of thoughts). An eval dataset should be in the format shown
Metrics like the exact match are used to compute the accuracy of completions.
Ragas
Ragas is an evaluation framework specifically targeted for retrieval augmented generation. It uses SOTA LLM-assisted methods to quantify the performance of RAG pipelines in multiple aspects like factuality, relevance, etc. You can also evaluate the performance of pipelines that you have built using frameworks like llama_index using it without needing an annotated evaluation dataset.
Challenges
Evaluating natural language generations still is an open research area. Many of the attributes we would like to evaluate here are very subjective like harmlessness, helpfulness, etc, and measuring factuality beyond a predefined set of annotated tasks is a very challenging task. For business building and maintaining such an evaluation dataset can also be very expensive and time-consuming because of factors like data and concept drift.
Conclusion
Evaluating LLM-based applications before productizing should be a key part of LLM workflow. This will act as a quality check and help you improve the performance of your pipeline over time. Through this article, we discussed and reviewed most of the possible ways by which you can do this. Let me know what you think in the comment section and if you're someone who enjoys similar content stay connected with me on Twitter.